省メモリ超高速マージソート
ランダムなデータに対して,クイックソートに匹敵する速さの不安定インプレースマージソート
(クイックソートが最速という常識への挑戦)
一般のマージソートでは,データの記憶領域と同じ程度の追加の記憶領域が必要です。インプレースマージソート(in-place merge
sort)とは,追加の記憶領域をほとんど使わずに行うマージソートです。
また,一般のマージソートでは,キーの値が同じ要素のソー
ト前の順序が,ソート後も変わらずに維持されます。このようなソートを安定ソートと言います。
一般のマージソートは,最速と言われているクイックソートよりも遅いようです。ただし,クイックソートは,安定ソートではありません。(私が作ったマージソートはクイッ
クソートよりも速いです。)
In-Place
Sorting With Merge Sort に,平均計算時間と最悪計算時間が共に O(n log
n)で,安定ソートではないインプレースマージソートがありますが,それは一般のマージソートより遅いものです。
私も,平均計算時間と最悪計算時間が共に O(n log n)で,安定ソートではないインプレースマージソートを作りました。再帰呼
び出しを用いていて,追加の記憶領域は O(log n)
です。(2025年1月)
その後,改良を重ねたところ,大量のランダムなデータに対する平均計算時間はクイックソートに匹敵するまでになりました。
ここで示すインプレースマージソートは,In-Place Sorting With Merge Sort
にあるインプレースマージソートに幾つかの改良を施した形になっていて,高速になっています。その1つは,部分列のソート法を次のように変えたことです。
データ列のある部分をソートする → データ列のある部分をソートされたデータ列にする
ここでは,データ列のある部分について,そこに存在するデータをソートするのではなく,その部分を,他の部分にあるデータも用いてソートされたデータ列に
したのです。
In-Place Sorting With Merge Sort
では,整列されたm個のデータと整列されたk個のデータを,整列されていないk個のデータを上手く用いて,整列されたm+k個のデータにしていました。
(整列されたm個,整列されていないk
個,整列されたk個) → (整列されたm+k個,整列されていないk個)
ここでのインプレースマージソートは,上記の操作を再帰的に繰り返しました。このことが,In-Place Sorting
With Merge Sort のソート法より高速になった最大の理由と思われます。
さらに,ソートされていないデータ
が少なくになったとき,ソートされていないデータをソートされたデータ列にマージするのに新たな手法を用い,クイックソートに匹敵する速度までになりまし
た。
また,小さなデータブロックに対するソートに挿入ソートを用いることにより高速化しましたが,クイックソートもこの方法で同様に高速化されます。
このソートは,最悪計算時間において,クイックソートやイントロソートよりも優れています。
世界最速のインプレースソートアルゴリズム
ランダムなデータに対してクイックソートとほぼ同じ速度を実現したコードです。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
typedef int d_type;// ソートするキーの型
//挿入ソート
#define INSERTION_SORT(m)\
int i=m;\
for (;i<n;i++){\
d_type tmp=array[i];\
int j=i-1;\
for (;j>=0 &&
array[j]>tmp;j--) array[j+1]=array[j];\
array[j+1]=tmp;\
}
//値を交換する関数
void swap(d_type *x,d_type *y){
d_type tmp=*x;
*x=*y;
*y=tmp;
}
// マージ (整列されたm個,整列されていないk 個,整列されたk個)
// → (整列されたm+k個,整列されていないk個) を行う関数
void mergeD(d_type a[], int m, int k){
d_type *b=a+m-1,*c=a+m+k-1,*d=a+m+2*k-1;
while (1) {
if (*b>*d) {
swap(b,c);
b--;c--;
if
(b<a) {
while(c>=a){
swap(c,d);
c--;d--;
}
return;
}
} else {
swap(c,d);
c--;d--;
if
(c<=b) return;
}
}
}
#define RATIO 0.2 //RATIO<=0.5
//整列されたn個の要素の配列を作る関数
void merge_sortD(d_type array[], int n){
if (n<50) {
INSERTION_SORT(1)
return;
}
int k=n*RATIO,m=n-k;//k=n/2をk=n*0.2に変えたら,なぜか高速化
merge_sortD(array,m);
merge_sortD(array+n,k);
mergeD(array,m,k);
}
#define CS(x,y) if (array[x]<array[y]) swap(array+x,array+y);
void merge_sort(d_type array[], int n){
int m=n*(1.0-RATIO);//mをできるだけ大きくした
merge_sortD(array,m);//整列されたm個の要素の配列を作る
while (1){//m個の要素の配列にk個の要素をマージすることを繰り返す
int k=(n-m)/2;
if (k<3) break;
int i=m,end=m+k-3;
for (;i<=end;i++) {int
j=i+2;CS(i,j);CS(i+1,j);CS(j,i+k)}
merge_sort(array+m+k,n-m-k);
mergeD(array,m,k);
m=m+k;
}
INSERTION_SORT(m) //残った要素を挿入ソートする
}
#undef CS
#undef RATIO
#undef INSERTION_SORT
int main(){
int n=100000000;
int i;
clock_t start,end;
d_type *array=malloc(n*sizeof(d_type));
srand((unsigned) time(NULL));
for (i=0;i<n;i++)
array[i]=rand()*(RAND_MAX+1)+rand();
start=clock();
merge_sort(array,n);
end=clock();
printf("%f秒
\n",(double)(end-start)/CLOCKS_PER_SEC);
for (i=1;i<n;i++) if(array[i-1]>array[i])
printf("%d %d\n",i,array[i]);
free(array);
return 0;
}
上記の merge_sort()
は,基本的なコードに次のコードを付加することにより,大きく高速化されています。
高速化のために付加した次のコードは,ソートされていない残ったデータのうちで,小さい値のデー
タをなるべく早くマージするためのものです。無くても動作しますので,速度を比較してみてください。
int i=m,end=m+k-3;
for (;i<=end;i++) {int
j=i+2;CS(i,j);CS(i+1,j);CS(j,i+k)}
なお,この2行は,高速化のために最初に考えた次の2行を,さらなる高速化のために改良したものです。
int i=m,end=m+k;
for (;i<end;i++) if (array[i]<array[i+k]) swap(array+i,array+i+k);
上記のプログラムがやっていることの概略は,次の様です。
1 全データの80%分のソートされた配列を作る。(この作業は,関数 merge_sortD() により高速に行われる)
2 残りの20%のうちの半分の10%をソートされた配列にし,それをソートされた80%の配列にマージして,ソートされた90%分の配列を作る。
3 残りの10%のうちの半分の5%をソートされた配列にし,それをソートされた90%の配列にマージして,ソートされた95%分の配列を作る。
4 残りの5%のうちの半分の2.5%をソートされた配列にし,それをソートされた95%の配列にマージして,ソートされた97.5%分の配列を作る。
…………
最初のコードでは,できるだけデータ数がほぼ等しいデータ群をマージしようとしていました。すなわち,m≒k
となる割合を多くすれば高速になると思い込んでいました。
ところが,コードの一部の「k=n/2」を「k=n*0.2」に変えたところ,不思議にも大きく速くなりました。
データ数比 1:1でマージしていたのを,4:1でマージするように変えると遅くなると思っていたのに,速くなるなんてびっくり。
私には理由は分かりませんが,「クイックソートのピボットは中央値でなく四分位数を選択したほうが高速」というブログを見て,もしかしたら分岐予測ミス確
率の関係かなと思っています。
注 RATIO
の値は0.2としていますが,もっと細かく,0.19や0.18とすると,実行するコンピュータによっては少しだけ高速になるかもしれません。
最悪計算時間がO(n log n) となることは,次の様に分かります。
① ほぼ同じ大きさのデータをマージする操作の計算時間の合計はO(n log n) で抑えられる。
② 大きさが大きく異なるデータをマージする回数はO(log n)で抑えられるから,それらの計算時間の和はO(n log n) で抑えられる。
③ 高速化のテクニックは計算時間を減少させるだけである。
注 関数 merge_sort() にある「m=n*(1.0-RATIO);//mをできるだけ大きくした」は,関数
merge_sortD()を用いるに当たり,次の条件が満たされれば良いと考えたからです。
m+m×RATIO+m×(RATIO)2+m×(RATIO)3+m×(RATIO)4+……≦n
ここで,無限等比級数の和の公式により
左辺=m/(1-RATIO)
よって
m/(1-RATIO)≦n
となるから
m≦n×(1-RATIO)
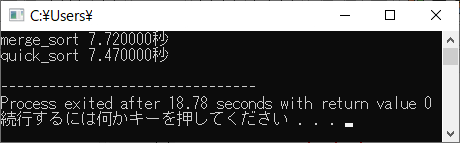
クイックソートとの比較
クイックソートは「世界最速のソートアルゴリズム」と言われることがありますが,素朴なままのクイックソートのコードでは上記のインプレースマージソート
より遅いです。
そこで,私ができるだけの高速化をしたクイックソートのコードを作り,世界最速のソートアルゴリズムを目指したインプレースマージソートのコードと計算時
間の比較をすることにしました。
私のパソコンで計測したところでは,このインプレースマージソートの1億個のランダムなデータに対する平均計算時間は,クイッ
クソートと同じくらいです。
実際にコンパイルして実行してみて下さい。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
typedef int d_type;// ソートするキーの型
#define INSERTION_SORT(m)\
int i=m;\
for (;i<n;i++){\
d_type tmp=array[i];\
int j=i-1;\
for (;j>=0 &&
array[j]>tmp;j--) array[j+1]=array[j];\
array[j+1]=tmp;\
}
void swap(d_type *x,d_type *y){
d_type tmp=*x;
*x=*y;
*y=tmp;
}
void mergeD(d_type a[], int m, int k){
d_type *b=a+m-1,*c=a+m+k-1,*d=a+m+2*k-1;
while (1) {
if (*b>*d) {
swap(b,c);
b--;c--;
if
(b<a) {
while(c>=a){
swap(c,d);
c--;d--;
}
return;
}
} else {
swap(c,d);
c--;d--;
if
(c<=b) return;
}
}
}
#define RATIO 0.2 //RATIO<=0.5
void merge_sortD(d_type array[], int n){
if (n<50) {
INSERTION_SORT(1)
return;
}
int k=n*RATIO,m=n-k;//k=n/2をk=n*0.2に変えたら,なぜか高速化
merge_sortD(array,m);
merge_sortD(array+n,k);
mergeD(array,m,k);
}
#define CS(x,y) if (array[x]<array[y]) swap(array+x,array+y);
void merge_sort(d_type array[], int n){
int m=n*(1.0-RATIO);//mをできるだけ大きくした
merge_sortD(array,m);//整列されたm個の要素の配列を作る
while (1){//m個の要素の配列にk個の要素をマージすることを繰り返す
int k=(n-m)/2;
if (k<3) break;
int i=m,end=m+k-3;
for (;i<=end;i++) {int
j=i+2;CS(i,j);CS(i+1,j);CS(j,i+k)}
merge_sort(array+m+k,n-m-k);
mergeD(array,m,k);
m=m+k;
}
INSERTION_SORT(m) //残った要素を挿入ソートする
}
#undef CS
#undef RATIO
void insertion_sort(d_type array[],int n){
INSERTION_SORT(1)
}
#undef INSERTION_SORT
d_type med3(d_type x,d_type y,d_type z){
if (x<y){
if
(y<z) return y;
else if (z<x) return x;
}else{
if
(z<y) return y;
else if (x<z) return x;
}
return z;
}
void quick_sort(d_type array[], int begin, int end){
int n=end-begin;
if (n<50){
insertion_sort(array+begin,n+1);
return;
}
d_type
pivot=med3(array[begin],array[begin+n/2],array[end]);
int l=begin,r=end;
while(1){
while(array[l]<pivot) l++;
while(array[r]>pivot) r--;
if(l>=r) break;
swap(array+l,array+r);
l++;r--;
}
quick_sort(array,begin,r);//l=r+1
quick_sort(array,r+1,end);
}
int main(){
int n=100000000;
int i;
clock_t start,end,end2;
d_type *array=malloc(n*sizeof(d_type));
d_type *array2=malloc(n*sizeof(d_type));
srand((unsigned) time(NULL));
for (i=0;i<n;i++){
array[i]=rand()*(RAND_MAX+1)+rand();
array2[i]=array[i];
}
start=clock();
merge_sort(array,n);
end=clock();
quick_sort(array2,0,n-1);
end2=clock();
printf("merge_sort %f秒
\n",(double)(end-start)/CLOCKS_PER_SEC);
printf("quick_sort %f秒
\n",(double)(end2-end)/CLOCKS_PER_SEC);
for (i=0;i<n;i++) if(array[i]!=array2[i])
printf("%d %d\n",array[i],array2[i]);
free(array);
free(array2);
return 0;
}
実行例
私のパソコンで実行してみましたが,CPUやコンパイラの設定によって結果が異なると思うので,皆さんのパソコンで試してみてください。
追加のメ
モリ量をデータのメモリ量の数%程度に抑えた,ランダム
なデータに対してクイックソートより速くて安定なマージソート
インプレースな安定マージソートで、平均計算時間と最悪計算時間が共に O(n log n) でクイックソートより速いものは理想ですが,私が調べた範囲では,そのようなものは存在しない様です。
また,追加のメモリ量がデータのメモリ量の平方根程度で計算時間が O(n log n) でクイックソートより速い安定マージソートも存在しない様です。
私の考察では,追加のメモリ量を O(√n) 程度に抑えたとき,比較の回数は O(n log n) ですが,データ交換回数が O(n (log n)2) となり,結果的に計算時間は O(n (log n)2) となってしまいます。
実際,省メモリマージソートとして知られている WikiSort において,データ数を1億や10億に設定して動作させると大分遅くなり,計算時間が O(n log n) という噂は誤りであることが分かります。
しかし,追加のメモリ量をデータのメモリ量の数%程度だけ使ってなら,ランダムなデータに対してクイックソートより速くて安定なマージ
ソートが作れるのではと考えました。
目標は,以下の条件の全てを満たすソートを作ることです。
マージソート系の安定ソート
平均計算時間と最悪計算時間は共にO(n
log n)
ランダムなデータに対して、クイックソートと同等以上の実行速度であること
ソートするデータが多いときに追加メモリの使用量を元のデータのメモリ量の1%程度まで抑えたい
コードは既存の省メモリ高速ソートよりも短くてシンプルにしたい
そこで,インプレースマージソートのコードを元に,追加メモリ使用量を元のデータのメモリ量の15%程度だけ使って安定なマージソートのコードを書いたと
ころ,
ク
イックソートよりも速くなりました。
課題は,「速度がクイックソートと同等以上という条件を保って,追加メモリ使用量を元のデータのメモリ量の1%程度まで減らす」,ということです。
追加のメモリ量を元のデータのメモリ量の15%程度に削減した
バージョン
通常のマージソートに対して,以下のような工夫をしました。ここで,整列された2つのデータをAとBとし,Bを作業記憶領域Wを用いてマージするとしま
す。
1 通常はAとBの両方をWにコピーするが,AだけをWにコピーするようにした。
2 AとBのデータ数の比率は通常は1:1だが,これを 0.15:0.85 すなわち 3:17 とした。
3 AとBをマージする関数merge()はポインタを用いて記述した。
4 小さなデータブロックに対するソートは挿入ソートを用いた。
5 マージのたびに作業記憶領域Wを確保せずに,W用に最初に一度だけ n*RATIO 個の容量の配列を確保して使い回した。
2により,追加のメモリ量は元のデータのメモリ量の15%程度に設定していますが,これは,メモリと速度の両方にメリットがあります。
実際,プログラムにある定数 RATIO
を0.5に変えると,AとBのデータ数の比率は1:1になりますが,このように変更すると,かなり低速になってしまいます。
よって,ランダムなデータをマージするときのデータ数の比率がほぼ1:1 のソートは,このソートより遅いと言えます。
このソートのコードを示します。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
typedef int d_type;// ソートするキーの型
void insertion_sort(d_type arr[],int n){
int i=1;
for (;i<n;i++){
d_type tmp=arr[i];
int j=i-1;
for (;j>=0 &&
arr[j]>tmp;j--) arr[j+1]=arr[j];
arr[j+1]=tmp;
}
}
void merge(d_type a[],int m,int n,d_type w[]){
int i=0;
for (;i<m;i++) w[i]=a[i];
d_type *b=a+m,*end=a+n;
while (1) {
if (*b<*w) {
*a++ = *b++ ;
if (b>=end) {
while(a<end) *a++ = *w++;
return;
}
} else {
*a++ = *w++;
if (a>=b) return;
}
}
}
#define RATIO 0.15
void merge_sort(d_type arr[],int n,d_type work[]) {
if (n<50) {
insertion_sort(arr,n);
return;
}
int m=n*RATIO;
merge_sort(arr,m,work);
merge_sort(arr+m,n-m,work);
if (arr[m-1]<=arr[m]) return;
merge(arr,m,n,work);
}
void MergeSort(d_type arr[], int n) {
d_type *work=malloc((int)(n*RATIO)*sizeof(d_type));
merge_sort(arr,n,work);
free(work);
}
#undef RATIO
int main(){
int n=100000000;
int i;
clock_t start,end;
d_type *arr=malloc(n*sizeof(d_type));
srand((unsigned) time(NULL));
for (i=0;i<n;i++)
arr[i]=rand()*(RAND_MAX+1)+rand();
start=clock();
MergeSort(arr,n);
end=clock();
printf("%f秒
\n",(double)(end-start)/CLOCKS_PER_SEC);
for (i=1;i<n;i++) if(arr[i-1]>arr[i])
printf("%d %d\n",i,arr[i]);
free(arr);
return 0;
}
上記のコードの平均計算時間と最悪計算時間はO(n log n)ですが,最良計算時間はO(n)
で,データが既にソートされている場合は非常に高速に処理できます。
そのために,関数merge_sort()のコードに次のif文を加えてあります。
if (arr[m-1]<=arr[m]) return;
追加のメモリ量を元のデータのメモリ量の5%程度に削減したバージョン
追加のメモリ量を5%程度に削減したバージョンは,上記の基本のコードより僅かに速度が低下しますが,クイックソートより速いようです。
また,追加のメモリ量を2%程度に削減するには,下記のコードの関数 MergeSort() にある wm=n*0.05+6
を wm=n*0.02+6 と変更するだけです。そうすると遅くなってしまいますが,それでもクイックソートと同じくらいの速さです。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
typedef int d_type;// ソートするキーの型
void insertion_sort(d_type arr[],int n){
int i=1;
for (;i<n;i++){
d_type tmp=arr[i];
int j=i-1;
for (;j>=0 &&
arr[j]>tmp;j--) arr[j+1]=arr[j];
arr[j+1]=tmp;
}
}
void merge(d_type a[],int m,int n,d_type w[]){
int i=0;
for (;i<m;i++) w[i]=a[i];
d_type *b=a+m,*end=a+n;
while (1) {
if (*b<*w) {
*a++ = *b++ ;
if (b>=end) {
while(a<end) *a++ = *w++;
return;
}
} else {
*a++ = *w++;
if (a>=b) return;
}
}
}
void merge_sort_wm(d_type arr[], int n, d_type work[], int wm) {
if (n<50){
insertion_sort(arr,n);
return;
}
int m=n*0.15;
merge_sort_wm(arr,m,work,wm);
merge_sort_wm(arr+m,n-m,work,wm);
if (arr[m-1]<=arr[m]) return;
while (m>0) {
if (m<wm) wm=m;
m=m-wm;
merge(arr+m,wm,n-m,work);
}
}
void MergeSort(d_type arr[], int n) {
int wm=n*0.05+6;
d_type *work=malloc(wm*sizeof(d_type));
merge_sort_wm(arr,n,work,wm);
free(work);
}
int main(){
int n=100000000;
int i;
clock_t start,end;
d_type *arr=malloc(n*sizeof(d_type));
srand((unsigned) time(NULL));
for (i=0;i<n;i++)
arr[i]=rand()*(RAND_MAX+1)+rand();
start=clock();
MergeSort(arr,n);
end=clock();
printf("%f秒
\n",(double)(end-start)/CLOCKS_PER_SEC);
for (i=1;i<n;i++) if(arr[i-1]>arr[i])
printf("%d %d\n",i,arr[i]);
free(arr);
return 0;
}
追加のメモリ量を元のデータのメモリ量の1%程度に削減したバージョン
追加のメモリ量を1%程度に削減するには wm=n*0.01+6
と変更すればできますが,クイックソートより遅くなってしまいます。そこで,追加のメモリ量が1%程度でもクイックソートと同じくらいの速さとなるよう,
さらなる改良をしてみました。
ウィキペディアの「ソート」のページでは,安定な In-place マージソートの平均計算時間と最悪計算時間は O(n(log n)2)
となっています。
そのようなコードは,Google検索やyahoo検索で「インプレースマージソート
回転と再帰を用いた超高速なC言語のコード」などと上手く検索すれば,AIが提供してくれます。(AIによるコードには,バグがあり動作しない可能性があ
ります。)
そのインプレースマージソートに上記の省メモリマージソートをうまく組み込めば,僅かなメモリでも実用に耐える速度の,安定マージソートが得られるので
はないかと考えました。
まずは,検索でAIより得た動作不良のインプレースマージソートのコードを動作するように直し,少しだけ変更を加えた,計算時間が O(n(log n)2)
の基本のインプレースマージソートのコードを示します。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
// 挿入ソート
void insertion_sort(int arr[],int i,int n){
for (;i<n;i++){
int tmp=arr[i];
int j=i-1;
for (;j>=0 && arr[j]>tmp;j--) arr[j+1]=arr[j];
arr[j+1]=tmp;
}
}
// ヘルパー関数: メモリの特定領域を反転させる(rotateの実装に使用)
void reverse(int* first, int* last) {
while (first < last) {
int temp = *first;
*first = *last;
*last = temp;
first++;
last--;
}
}
// [first, mid) と [mid, last) の要素を入れ替える
void rotate(int* first, int* mid, int* last) {
if (first == mid || mid == last) return;
reverse(first, mid-1);
reverse(mid, last-1);
reverse(first, last-1);
}
// キー以上の最初の位置
int lower_bound(int arr[], int low, int high, int key) {
while (low < high) {
int mid = low + (high - low) / 2;
if (arr[mid] >= key)
high = mid;
else
low = mid + 1;
}
return low;
}
// キーより大きい最初の位置
int upper_bound(int arr[], int low, int high, int key) {
while (low < high) {
int mid = low + (high - low) / 2;
if (arr[mid] > key)
high = mid;
else
low = mid + 1;
}
return low;
}
// 再帰的In-place マージ関数
void inPlaceMerge(int arr[], int l, int m, int r) {
// マージ不要な場合
if (m <= l || r < m) return;
// 前半の最大値が後半の最小値以下の場合
if (arr[m-1] <= arr[m]) return;
// マージするデータ数が少なくなったとき
if (r-l<=35){
insertion_sort(arr+l, m-l, r-l+1);
return;
}
// 分割点(回転させる境界)を見つける
int i, j;
if (m - l >= r - m + 1) {
i = l + (m - l) / 2;
// 範囲 [m, r+1) で arr[i] 以上に大きい最初の要素を探す
j=lower_bound(arr, m, r+1, arr[i]);
} else {
j = m + (r - m + 1) / 2;
// 範囲 [l, m) で arr[j] より大きい最初の要素を探す
i=upper_bound(arr, l, m, arr[j]);
}
// 回転して領域を融合 (iからm-1とmからj-1を交換)
rotate(arr+i, arr+m, arr+j);
// 新しい分割点
m = i + (j - m);
// 再帰的にマージ
inPlaceMerge(arr, l, i, m - 1);
inPlaceMerge(arr, m , j, r);
}
// ソート関数
void inPlaceMergeSort(int arr[], int l, int r) {
//if (r - l <= 0) return;
int n = r - l + 1;
if (n<50) { // 小さいところは挿入ソートで高速化
insertion_sort(arr+l,1, n);
return;
}
int m = l + n / 2;
inPlaceMergeSort(arr, l, m - 1);
inPlaceMergeSort(arr, m , r);
inPlaceMerge(arr, l, m , r);
}
int main(){
int n=100000000;
int i;
clock_t start,end;
int *arr=malloc(n*sizeof(int));
srand((unsigned) time(NULL));
for (i=0;i<n;i++)
arr[i]=rand()*(RAND_MAX+1)+rand();
start=clock();
inPlaceMergeSort(arr,0,n-1);
end=clock();
printf("%f秒
\n",(double)(end-start)/CLOCKS_PER_SEC);
for (i=1;i<n;i++) if(arr[i-1]>arr[i])
printf("%d %d\n",i,arr[i]);
free(arr);
return 0;
}
次に,基本のインプレースマージソートの挿入ソートの部分を省メモリマージソートに変え,追加のメモリ量を元のデータのメモリ量の1%程度にしたコードを
示します。
上記のコードの関数 rotate() は回転を用いて移動を行うという素晴らしいアイデアですが,回転を用いない関数 exchange()
をせっかく考えたので,次のコードでは,それに替えてあります。
速度は,高速化の工夫がされたクイックソートと同じくらいです。
なお,wm=n*0.001+6 とすれば追加のメモリ量を0.1%程度に削減できます。
また,例えば,wm=100 とすればインプレースマージソートになり,#include <math.h> を付け加えて
wm=sqrt(n) とすれば,ほぼインプレースマージソートになります。
これらの場合でも極端な速度低下は起きません。
基本のインプレースマージソートに対して,次のような変更を行いました。
1 ソート関数 inPlaceMergeSort() において,n<50 で挿入ソートに切り換えているが,n/20<=wm
で省メモリマージソートに切り換えるようにした。
2 ソート関数 inPlaceMergeSort() において,m = l + n / 2 と2分割して再帰しているが,m = l + n/4
と 1:4 に分割して再帰した。
3 コードを短くシンプルにするために,関数 upper_bound() は使わないようにした。
4 マージ関数 inPlaceMerge() において,マージ不要な m <= l || r < m
となるまで再帰を進めているが,m-l<=wm*3+10 という条件で省メモリマージソートのマージに切り換えるようにした。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
typedef int d_type;// ソートするキーの型
void insertion_sort(d_type arr[],int n){
int i=1;
for (;i<n;i++){
d_type tmp=arr[i];
int j=i-1;
for (;j>=0 &&
arr[j]>tmp;j--) arr[j+1]=arr[j];
arr[j+1]=tmp;
}
}
void merge(d_type a[],int m,int n,d_type w[]){
int i=0;
for (;i<m;i++) w[i]=a[i];
d_type *b=a+m,*end=a+n;
while (1) {
if (*b<*w) {
*a++ = *b++ ;
if (b>=end) {
while(a<end) *a++ = *w++;
return;
}
} else {
*a++ = *w++;
if (a>=b) return;
}
}
}
void merge_wm(d_type arr[], int m, int n, d_type work[], int wm){
while (m>0) {
if (m<wm) wm=m;
m=m-wm;
merge(arr+m,wm,n-m,work);
}
}
void merge_sort_wm(d_type arr[], int n, d_type work[], int wm) {
if (n<50){
insertion_sort(arr,n);
return;
}
int m=n*0.15;
merge_sort_wm(arr,m,work,wm);
merge_sort_wm(arr+m,n-m,work,wm);
if (arr[m-1]<=arr[m]) return;
merge_wm(arr,m,n,work,wm);
}
// 2つの変数の値を交換する
void swap(d_type *x, d_type *y){
d_type tmp = *x;
*x = *y;
*y = tmp;
}
// 範囲 [0, m+n) 内で、[0, m) と[m, m+n) の要素の前後を入れ替える
void exchange(d_type arr[], int m, int n) {
if (n <= 0) return;
int i = m + n - 1;
while (m > 0) {
for (; i >= n; i--)
swap(arr + i, arr + i - n);
while (m >= n) m = m - n;
// m = m % n
n = n - m;
}
}
// キー以上の最初の位置
int lower_bound(d_type arr[], int low, int high, d_type key) {
while (low < high) {
int mid = low + (high - low)
/ 2;
if (arr[mid] >= key)
high
= mid;
else
low
= mid + 1;
}
return low;
}
// In-place マージ関数
void inPlaceMerge(d_type arr[], int l, int m, int r, d_type work[], int
wm) {
if (r < m) return;
if (arr[m-1] <= arr[m]) return;
// マージするデータ数が少なくなったとき
if (m-l<=wm*3+10){
merge_wm(arr+l, m-l, r-l+1,
work, wm);
return;
}
int i = l + (m - l) / 2;
int j=lower_bound(arr, m, r+1, arr[i]);
exchange(arr + i, m - i, j - m);
m = i + (j - m);
inPlaceMerge(arr, l, i, m - 1,work,wm);
inPlaceMerge(arr, m , j, r,work,wm);
}
// ソート関数
void inPlaceMergeSort(d_type arr[], int l, int r, d_type work[], int
wm) {
int n=r-l+1;
if (n/20<=wm){
merge_sort_wm(arr+l,n,work,wm);
return;
}
int m = l + n/4;
inPlaceMergeSort(arr, l, m-1,work,wm);
inPlaceMergeSort(arr, m , r,work,wm);
inPlaceMerge(arr, l, m , r,work,wm);
}
void MergeSort(d_type arr[], int n) {
int wm=n*0.01+6; // wn>=1 で動作
d_type *work=malloc(wm*sizeof(d_type));
inPlaceMergeSort(arr,0,n-1,work,wm);
free(work);
}
int main(){
int n=100000000;
int i;
clock_t start,end;
d_type *arr=malloc(n*sizeof(d_type));
srand((unsigned) time(NULL));
for (i=0;i<n;i++)
arr[i]=rand()*(RAND_MAX+1)+rand();
start=clock();
MergeSort(arr,n);
end=clock();
printf("%f秒
\n",(double)(end-start)/CLOCKS_PER_SEC);
for (i=1;i<n;i++) if(arr[i-1]>arr[i])
printf("%d %d\n",i,arr[i]);
free(arr);
return 0;
}
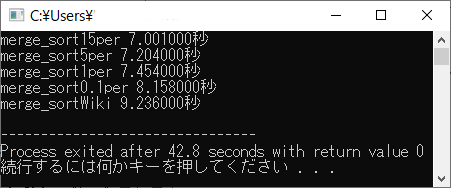
追加のメモリ量を,データ数の15%程度にしたコードと,5%程度にしたコードと,1%程度にしたコードと,0.1%程度にしたコードと,Wikipediaにある基本的なマージソー
トのコードとの比較
上記のコードとWikipediaにある高速化の工夫をしていないマージソートのコードの速度を比較しようと思いました。
しかし,挿入ソートを用いていないWikipediaのマージソートでは比較にならないので,Wikipediaのコードに挿入ソートを書き足して高速化
しました。
これに加え,midの式を mid = (left + right) / 2 → mid = left + (right - left) / 4
と変えて,さらに高速にしました。
Wikipediaのコードにこれらの高速化を施した「merge_sortWiki」と比較してみました。これにより,上記のコードが実用的な性能を持
つことが示されました。
関数merge()をポインタを用いて記述したことについて
関数merge()は,ポインタを使わずに次の様に書くことができます。こちらの方が平易なのですが,残念ながら遅くなってしまいます。
void merge(d_type arr[],int m,int n,d_type work[]) {
int i=0,j=0,k=0;
for (;i<m;i++) work[i]=arr[i];
while (1) {
if (arr[i]<work[j]){
arr[k++]=arr[i++];
if
(i>=n){
while (j<m) arr[k++]=work[j++];
return;
}
}else{
arr[k++]=work[j++];
if
(j>=m) return;
}
}
}
追加のメモリ量を元のデータのメモリ量の1%程度に削減したバージョンにおいて,追加のメモリを自動的に変えて最速にする工夫
このバージョンでは,配列 work[] が利用するメモリ数 wm は1以上で動作してwn が大きいほど速くなり,wm がnの15%以上のときに最速になります。
したがって,関数 MergeSort() を次の様に変えると,work[] が使用できるメモリに応じて自動的に,安定性が保たれたまま最速でソートします。
void MergeSort(d_type arr[], int n) {
int wm=n*0.15+6; // wn>=1 で動作
do {
d_type *work=malloc(wm*sizeof(d_type));
if (work!=NULL){
inPlaceMergeSort(arr,0,n-1,work,wm);
free(work);
return;
}
wm=wm/2;
} while (wm>0);
//作業用メモリが確保できないとき
d_type work[1];
inPlaceMergeSort(arr,0,n-1,work,1);
}
安定ソートであることを構造体を用いて確認するコード
構造体をソートできるように改造し,安定ソートであることを確認できるようにしました。
構造体 d_type と関数 compare() の定義を変更すれば,マージソート本体を変更すること無く,他の構造体でもソートできます。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
typedef struct{
int value; // ソートする値
int index; // 元の順序(インデックス)
} d_type;
int compare(const void *a, const void *b) {
int x = ((d_type *)a)->value;
int y = ((d_type *)b)->value;
if(x<y) return -1;
if(x>y) return 1;
return 0;
}
void insertion_sort(d_type arr[],int n){
int i=1;
for (;i<n;i++){
d_type tmp=arr[i];
int j=i-1;
for (;j>=0 && compare(arr+j,&tmp)>0;j--) arr[j+1]=arr[j];
arr[j+1]=tmp;
}
}
void merge(d_type a[],int m,int n,d_type w[]){
int i=0;
for (;i<m;i++) w[i]=a[i];
d_type *b=a+m,*end=a+n;
while (1) {
if (compare(b,w)<0) {
*a++ = *b++;
if (b>=end) {
while(a<end) *a++ = *w++;
return;
}
} else {
*a++ = *w++;
if (a>=b) return;
}
}
}
void merge_wm(d_type arr[], int m, int n, d_type work[], int wm){
while (m>0) {
if (m<wm) wm=m;
m=m-wm;
merge(arr+m,wm,n-m,work);
}
}
void merge_sort_wm(d_type arr[], int n, d_type work[], int wm) {
if (n<50){
insertion_sort(arr,n);
return;
}
int m=n*0.15;
merge_sort_wm(arr,m,work,wm);
merge_sort_wm(arr+m,n-m,work,wm);
if (compare(arr+m-1,arr+m)<=0) return;
merge_wm(arr,m,n,work,wm);
}
// 2つの変数の値を交換する
void swap(d_type *x, d_type *y){
d_type tmp = *x;
*x = *y;
*y = tmp;
}
void exchange(d_type arr[], int m, int n) {
if (n <= 0) return;
int i = m + n - 1;
while (m > 0) {
for (; i >= n; i--) swap(arr + i, arr + i - n);
while (m >= n) m = m - n; // m = m % n
n = n - m;
}
}
// キー以上の最初の位置
int lower_bound(d_type arr[], int low, int high, d_type key) {
while (low < high) {
int mid = low + (high - low) / 2;
if (compare(arr+mid,&key)>=0)
high = mid;
else
low = mid + 1;
}
return low;
}
// In-place マージ関数
void inPlaceMerge(d_type arr[], int l, int m, int r, d_type work[], int wm) {
if (r < m) return;
if (compare(arr+m-1,arr+m)<=0) return;
// マージするデータ数が少なくなったとき
if (m-l<= wm*3+10){
merge_wm(arr+l, m-l, r-l+1, work, wm);
return;
}
int i, j;
i = l + (m - l) / 2;
j=lower_bound(arr, m, r+1, arr[i]);
exchange(arr + i, m - i, j - m);
m = i + (j - m);
inPlaceMerge(arr, l, i, m - 1,work,wm);
inPlaceMerge(arr, m , j, r,work,wm);
}
// ソート関数
void inPlaceMergeSort(d_type arr[], int l, int r, d_type work[], int wm) {
int n=r-l+1;
if (n/20<=wm){
merge_sort_wm(arr+l,n,work,wm);
return;
}
int m = l + n/4;
inPlaceMergeSort(arr, l, m-1,work,wm);
inPlaceMergeSort(arr, m , r,work,wm);
inPlaceMerge(arr, l, m , r,work,wm);
}
void MergeSort(d_type arr[], int n) {
int wm=n*0.15+6; // wn>=1 で動作
do {
d_type *work=malloc(wm*sizeof(d_type));
if (work!=NULL){
inPlaceMergeSort(arr,0,n-1,work,wm);
free(work);
return;
}
wm=wm/2;
} while (wm>0);
//作業用メモリが確保できないとき
d_type work[1];
inPlaceMergeSort(arr,0,n-1,work,1);
}
// 安定性をチェックする関数
void check_stability(d_type arr[], int n) {
int i;
for (i = 0; i < n - 1; i++) {
if (arr[i].value==arr[i+1].value) {
if (arr[i].index > arr[i + 1].index){
printf("不安定です \n");
return;
}
}
}
printf("安定の様です \n");
}
int main() {
int n=100000000;
int i;
clock_t start,end;
d_type *arr=(d_type *)malloc(n*sizeof(d_type));
srand((unsigned) time(NULL));
for (i=0;i<n;i++){
arr[i].value=rand();
arr[i].index=i;
}
start=clock();
MergeSort(arr, n);
//qsort(arr, n, sizeof(d_type), compare);
end=clock();
printf("%f秒 \n",(double)(end-start)/CLOCKS_PER_SEC);
for (i=1;i<n;i++) if(arr[i-1].value > arr[i ].value) printf("%d %d\n",i,arr[i].value);
// 結果判定
check_stability(arr, n);
return 0;
}
汎用不安定ソートである qsort の代わりとなる汎用安定ソート msort
C言語の標準ライブラリ関数 qsort は, stdlib.h の中で宣言されている汎用ソートで,使いやすく実用には十分な速度で,欠点は不安定ソートであることです。
上記のマージソートを手直しすれば,qsort と同じインターフェース(比較関数の引数など)の汎用省メモリ安定ソートが作れるのではと考え,実際にそれを作成して msort と名付けました。
速度は,残念ながら極端に遅くなり,qsort よりも遅くなってしまいました。qsortには,高速化のための高度な工夫がされている様です。
追加のメモリ量は、初期設定では元のデータのメモリ量の8%程度で,メモリ不足の場合は追加のメモリを自動的に削減します。
コードのコメントになっている qsort(arr, n, sizeof(d_type), compare) を実行して,msort と qsort を比較してみて下さい。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
// qsort() と同じ使い方にするには、次の様にします
// 以下のコードの「msort.h の終わり」までを msort.h として保存し、その部分を削除する。
// #include "msort.h" をこのコードに付け加える。
//msort.h の始まり
#include <string.h>
#define int_CMP int (*CMP)(const void *, const void *)
void insertion_sort(char *arr, size_t n, size_t size, int_CMP,char *work) {
char *i=arr+size,*last=arr+n*size;
for (; i<last; i+=size) {
char *j=i;
memcpy(work,j,size);
for (;j>arr && CMP(j-size,work)>0;j-=size) memcpy(j,j-size,size);
memcpy(j,work,size);
}
}
void merge(char *a,size_t m,size_t n, size_t size, int_CMP,char *w){
memcpy(w,a,m*size);
char *b=a+m*size,*end=a+n*size;
while (1) {
if (CMP(b,w)<0) {
memcpy(a,b,size);
a+=size;b+=size;
if (b>=end) {
while(a<end) {
memcpy(a,w,size);
a+=size;w+=size;
}
return;
}
} else {
memcpy(a,w,size);
a+=size;w+=size;
if (a>=b) return;
}
}
}
void merge_wm(char *arr, size_t m, size_t n, size_t size,int_CMP, char *work, size_t wm){
while (m>0) {
if (m<wm) wm=m;
m=m-wm;
merge(arr+m*size,wm,n-m,size,CMP,work);
}
}
void merge_sort_wm(char *arr, size_t n, size_t size, int_CMP, char *work, size_t wm) {
if (n<=16){
insertion_sort(arr,n,size,CMP,work);
return;
}
size_t m=n*0.3;
merge_sort_wm(arr,m,size,CMP,work,wm);
merge_sort_wm(arr+m*size,n-m,size,CMP,work,wm);
if (CMP(arr+(m-1)*size,arr+m*size)<=0) return;
merge_wm(arr,m,n,size,CMP,work,wm);
}
void exchange(char *arr, size_t m, size_t n, size_t size,char *work) {
if (n <= 0) return;
char *i = arr+(m + n - 1)*size;
while (m > 0) {
size_t nsize=n*size;
char *left=arr+nsize;
for (; i >= left; i-=size) { //変数の値を交換する
char *j = i-nsize;
memcpy(work, i, size);
memcpy(i, j, size);
memcpy(j, work, size);
}
while (m >= n) m = m - n; // m = m % n
n = n - m;
}
}
// キー以上の最初の位置
size_t lower_bound(char *arr, size_t low, size_t high, size_t size, char *key, int_CMP) {
while (low < high) {
size_t mid = low + (high - low) / 2;
if (CMP(arr+mid*size,key)>=0)
high = mid;
else
low = mid + 1;
}
return low;
}
// In-place マージ関数
void inPlaceMerge(char *arr, size_t l, size_t m, size_t r, size_t size, int_CMP, char *work, size_t wm) {
if (r < m) return;
if (CMP(arr+(m-1)*size,arr+m*size)<=0) return;
// マージするデータ数が少なくなったとき
if (m-l<= wm*3+10){
merge_wm(arr+l*size, m-l, r-l+1, size, CMP, work, wm);
return;
}
size_t i, j;
i = l + (m - l) / 2;
j=lower_bound(arr, m, r+1,size, arr+i*size,CMP);
exchange(arr + i*size, m - i, j - m, size, work);
m = i + (j - m);
inPlaceMerge(arr, l, i, m - 1,size, CMP,work,wm);
inPlaceMerge(arr, m , j, r,size, CMP,work,wm);
}
// ソート関数
void inPlaceMergeSort(char *arr, size_t l, size_t r, size_t size, int_CMP, char *work, size_t wm) {
size_t n=r-l+1;
if (n/10 <= wm){
merge_sort_wm(arr+l*size,n, size, CMP,work,wm);
return;
}
size_t m = l + n/4;
inPlaceMergeSort(arr, l, m-1, size, CMP,work,wm);
inPlaceMergeSort(arr, m , r, size, CMP,work,wm);
inPlaceMerge(arr, l, m , r, size, CMP,work,wm);
}
void msort(void *base, size_t n, size_t size, int_CMP) {
char *arr = (char *)base;
size_t wm=n*0.08+6; // wn>=1 で動作
do {
char *work=(char *)malloc(wm*size);
if (work!=NULL){
inPlaceMergeSort(arr,0,n-1, size, CMP,work,wm);
free(work);
return;
}
wm=wm/2;
} while (wm>0);
//作業用メモリが確保できないとき
char work[size];
inPlaceMergeSort(arr,0,n-1, size, CMP,work,1);
}
#undef int_CMP
// msort.h の終わり
typedef struct{
int value; // ソートする値
int index; // 元の順序(インデックス)
} d_type;
int compare(const void *a, const void *b) {
int x = ((d_type *)a)->value;
int y = ((d_type *)b)->value;
if(x<y) return -1;
if(x>y) return 1;
return 0;
}
// 安定性をチェックする関数
void check_stability(d_type arr[], int n) {
int i;
for (i = 0; i < n - 1; i++) {
if (arr[i].value==arr[i+1].value) {
if (arr[i].index > arr[i + 1].index){
printf("不安定です \n");
return;
}
}
}
printf("安定の様です \n");
}
int main() {
size_t n=100000000;
int i;
clock_t start,end;
d_type *arr=(d_type *)malloc(n*sizeof(d_type));
srand((unsigned) time(NULL));
for (i=0;i<n;i++){
arr[i].value=rand()*(RAND_MAX+1)+rand();
arr[i].index=i;
}
start=clock();
msort(arr, n, sizeof(d_type), compare);
//qsort(arr, n, sizeof(d_type), compare);
end=clock();
printf("%f秒 \n",(double)(end-start)/CLOCKS_PER_SEC);
for (i=1;i<n;i++) if(arr[i-1].value > arr[i ].value) printf("%d %d\n",i,arr[i].value);
check_stability(arr, n);// 安定性の判定
free(arr);
return 0;
}
理由が大して分からずマジックのように速くなったソートですが,マー
ジソートの考案者のフォン・ノイマンもマジマジと見ているかもしれません。